AI-utvecklingen är till största delen öppen källkod, så AI-modeller tränas på liknande träningsmönster.
- WizardLM, eller WizardCoder, är en av de bästa AI-kodarna på marknaden just nu.
- WizardLM hävdar att Phind, en konkurrent, använde WizardCoder-modellen för att träna sig själv, utan att kreditera originalarbetet.
- Företaget bakom Phind förnekar påståendena från WizardLM.

Kom ihåg WizardCoder, AI-kodaren som vi nyligen täckte här i Windows Report? Vi utropade som den bästa AI-kodaren i världen, då och av goda skäl. WizardCoder, som också går under namnet WizardLM, kan korrekt skriva kodblock av sig själv. Och som ett AI-verktyg kan det i hög grad hjälpa programmerare att koda snabbare.
Och dess rykte har vuxit så mycket att det verkar som om WizardLM: s träningsprocess har replikerats till en AI-modell från tredje part, kallad Phind. Men här är haken: det Microsoft-finansierade teamet bakom WizardLM hävdar att Phind-teamet stal allt deras arbete, utan att ens kreditera dem.
Om du kommer ihåg,
WizardLM är en öppen källkodsmodell som kan användas för att träna din egen AI-modell. Dock, AI-partnerskap är den verkliga drivkraften bakom AI-utveckling, och WizardLM-teamet vill bara krediteras när deras arbete används för att träna andra AI-modeller.Företaget bakom Phind, men förnekar att de har använt WizardLM för att bygga modellen, även om WizardLM-teamet har bevis för att deras arbete verkligen användes för att skapa Phind-modellen från tredje part.
WizardLM och Phind: En första dokumenterad fejd mellan AI-modeller
Enligt WizardLM:
- Phind använder en data som heter WizardCoder-stil som utförs från WizardCoder Evol-Instruct-metoden för att träna sin V1 Code Llama-modell.
- Sedan fortsätter de att använda metoder från en WizardCoder-modell för att träna sin V2-modell.
- De erkänner inte användningen och de hävdar att de inte använder något från WizardCoder.
Alla dessa upptäcktes och greps med bilder och skärmdumpar som beskriver den uppenbara konflikten. Å andra sidan säger Phind-teamet att de inte använde WizardLM-modellen för att träna Phind.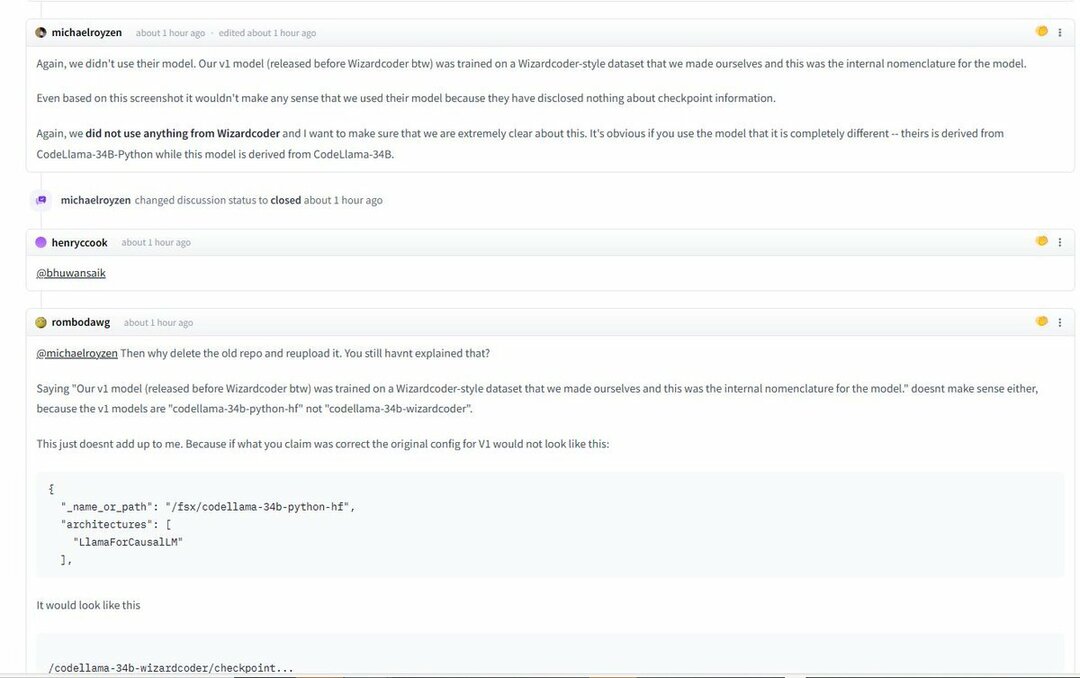
Återigen, vi använde inte deras modell. Vår v1-modell (släpptes före WizardCoder) tränades på en datauppsättning i WizardCoder-stil som vi gjorde själva och detta var den interna nomenklaturen för modellen.
Phind team
Vissa personer föreslog att ett partnerskap eller ett samarbete mellan de två parterna skulle göra mer för att främja AI-utveckling än att bråka om det. Sanningen är att AI-utveckling mestadels är öppen källkod, hela tiden, så modeller kommer att ha liknande om inte exakta träningsmönster.
Men om din AI-modell är tränad på en annan modells träningsmönster, är det bara rättvist att kreditera arbetet. Detta kan trots allt vara grunden för ett långt och fruktbart partnerskap.
Vad tycker du om den här situationen?