Новая структура совершит революцию в моделях ИИ.
- Фреймворк позволяет иметь неограниченную длину контекста.
- Неограниченная длина контекста означает более персонализированный разговор с моделями ИИ.
- По сути, это следующий шаг ИИ к полному приближению к человеку.

Microsoft была в авангарде обучения ИИ и инструментов ИИ в целом. Copilot появится в Windows 11 очень скоро, как часть обновлений Windows. ИИ проникает в Microsoft Teams с интеллектуальное резюме, помогающее людям работать легче.
Bing также является одним из самых интересных инструментов искусственного интеллекта., а его функции позволяют оптимизировать как вашу работу, так и вашу навигацию в Интернете.
Но ранее на этой неделе Microsoft также представила, что Orca 13B скоро станет открытым исходным кодом. Orca 13B — это небольшая модель ИИ, которая работает с тем же качеством и скоростью, что и другие модели ИИ, такие как ChatGPT.
Теперь, в битве ИИ и исследований ИИ, Microsoft предлагает LongMem, гипотетическая структура и языковая модель ИИ.
Согласно этой ветке Reddit, LongMem допускает неограниченную длину контекста при уменьшенном использовании памяти GPU и CPU. Все это делается на более высокой скорости.
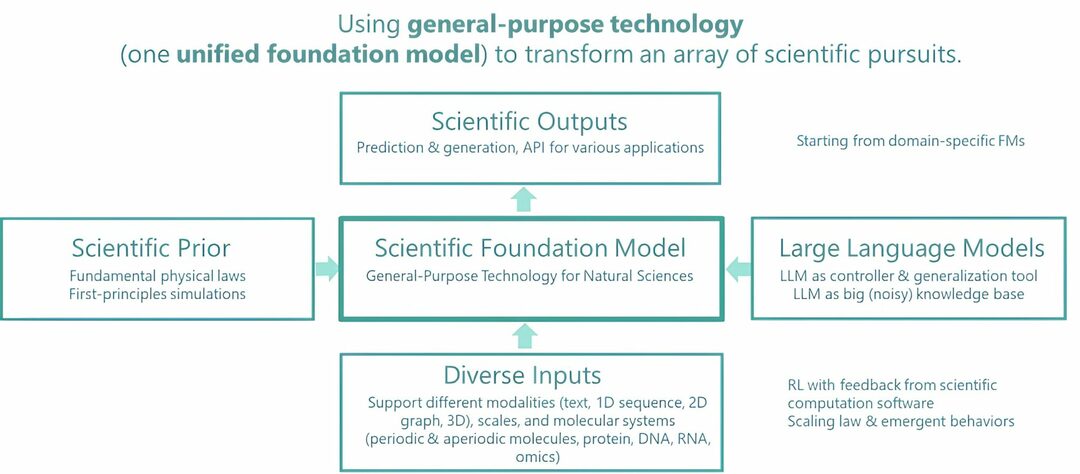
Microsoft Research предлагает новую структуру LongMem, позволяющую использовать неограниченную длину контекста, а также уменьшать использование памяти графического процессора и повышать скорость логического вывода. Код будет открытым
к ты/ламаШилл в МестнаяLLaMA
Является ли LongMem ответом Microsoft для неограниченной длины контекста?
Итак, чтобы понять, что значит иметь неограниченную длину контекста, нам сначала нужно понять, что означает длина контекста?
Длина контекста относится к количеству токенов (слов, знаков и т. д.), разрешенных моделью, ее вводом и выводом, а также вашим.
Например, ChatGPT имеет ограниченное количество токенов, что означает, что длина его контекста также ограничена. Как только ChatGPT преодолеет этот предел, все непрерывное взаимодействие, которое у вас было с ним до этого момента, потеряет всякое значение. Или, лучше сказать, он будет сброшен.
Так что, если вы начинаете разговор с ChatGPT на тему Windows, и этот разговор длится дольше, чем ограниченный контекст длины, то инструмент ИИ потеряет контекст и либо начнет отклоняться от темы, либо весь разговор перезагрузить.
Неограниченная длина контекста гарантирует, что этого не произойдет, а модель ИИ будет продолжать отвечать вам по теме, а также изучать и адаптировать информацию, когда вы говорите ей о Windows.
Это означает, что модель ИИ также будет персонализировать разговор в соответствии с вашим вводом, поэтому контекст должен иметь неограниченную длину.
Как работает LongMem?
Microsoft обещает именно это своим новым исследованием фреймворка LongMem. LongMem позволит большим языковым моделям запоминать долгосрочные контексты и использовать долговременную память при сниженной мощности процессора.
Фреймворк состоит из замороженной большой языковой модели в качестве кодировщика памяти, остаточной боковой сети. как средство извлечения и чтения памяти, а также кэшированный банк памяти, в котором хранятся пары ключ-значение из прошлых контексты.
В исследовании, проведенном Microsoft, эксперименты показывают, что LongMem превосходит базовые показатели в моделировании длинного текста, понимании длинного контекста и задачах обучения в контексте с дополненной памятью. Кроме того, долговременная память позволяет использовать больше демонстрационных примеров для лучшего обучения.
И хорошая новость заключается в том, что LongMem будет с открытым исходным кодом. Таким образом, вы сможете изучить его и узнать, как внедрить фреймворк в свою собственную модель ИИ. Вы можете проверить его профиль GitHub здесь.
И если вам интересно прочитать всю исследовательскую работу по фреймворку, зайди сюда и посмотри.
Что вы думаете об этом новом технологическом прорыве? Изменит ли это то, как работают модели ИИ? Не забудьте сообщить нам свои мысли и мнения ниже.