AI-ontwikkelingen zijn grotendeels open source, dus AI-modellen worden getraind op vergelijkbare trainingspatronen.
- WizardLM, of WizardCoder, is momenteel een van de beste AI-codeerders op de markt.
- WizardLM beweert dat Phind, een concurrent, het WizardCoder-model gebruikte om zichzelf te trainen, zonder het originele werk te vermelden.
- Het bedrijf achter Phind ontkent de beweringen van WizardLM.

Onthoud WizardCoder, de AI-coder die we onlangs hier bij Windows Report hebben besproken? Wij prezen als de beste AI-codeur ter wereld, toen, en met goede reden. WizardCoder, ook wel WizardLM genoemd, is in staat zelf codeblokken correct te schrijven. En als AI-tool kan het programmeurs enorm helpen sneller te coderen.
En de reputatie is zo sterk gegroeid dat het erop lijkt dat het trainingsproces van WizardLM is gerepliceerd in een AI-model van een derde partij, genaamd Phind. Maar hier is het addertje onder het gras: het door Microsoft gefinancierde team achter WizardLM beweert dat het Phind-team al hun werk heeft gestolen, zonder ze zelfs maar te crediteren.
Als je je herinnert, WizardLM is een open-sourcemodel dat kan worden gebruikt om uw eigen AI-model te trainen. Echter, AI-partnerschappen zijn de echte drijvende kracht achter de AI-ontwikkeling, en het WizardLM-team wil alleen maar gecrediteerd worden wanneer hun werk wordt gebruikt om andere AI-modellen te trainen.
Het bedrijf achter Phindontkent echter dat het WizardLM heeft gebruikt om het model te bouwen, ook al heeft het WizardLM-team bewijs dat hun werk inderdaad is gebruikt om het Phind-model van derden te creëren.
WizardLM en Phind: een eerste gedocumenteerde vete tussen AI-modellen
Volgens WizardLM:
- Phind gebruikt een gegevensset met de naam WizardCoder-stijl, uitgevoerd volgens de WizardCoder Evol-Instruct-methode om hun V1 Code Llama-model te trainen.
- Vervolgens blijven ze methoden uit een WizardCoder-model gebruiken om hun V2-model te trainen.
- Ze erkennen het gebruik niet en beweren dat ze niets van WizardCoder gebruiken.
Deze werden allemaal opgemerkt en aangehouden met foto's en schermafbeeldingen die het schijnbare conflict detailleerden. Aan de andere kant zegt het Phind-team dat ze het WizardLM-model niet hebben gebruikt om Phind te trainen.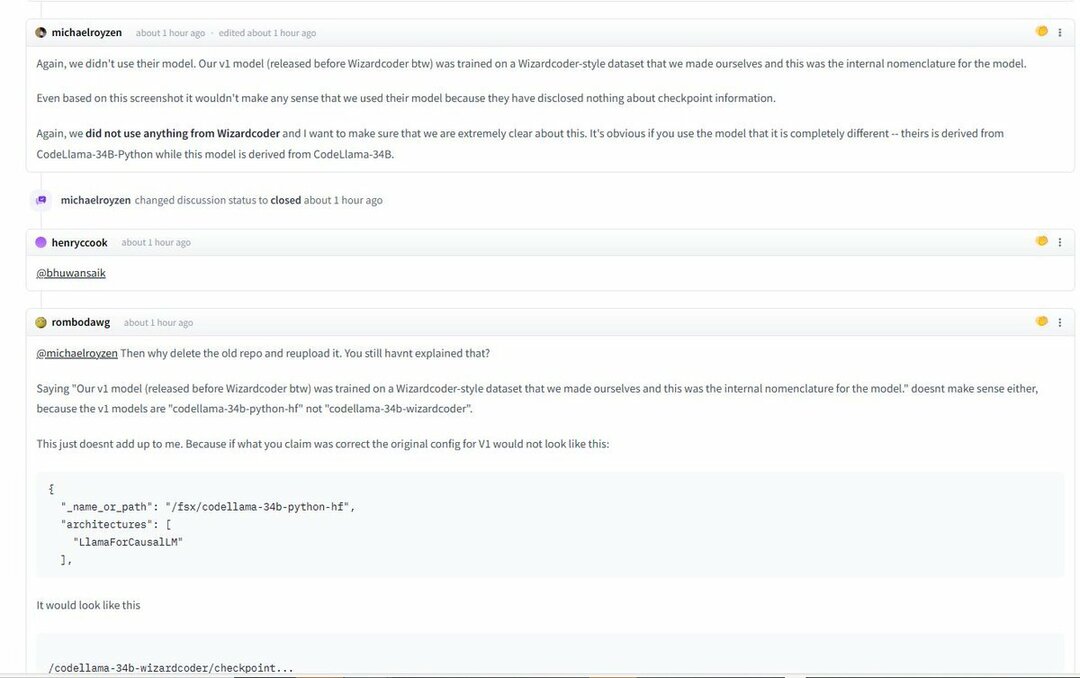
Nogmaals, we hebben hun model niet gebruikt. Ons v1-model (uitgebracht vóór WizardCoder) werd getraind op een dataset in WizardCoder-stijl die we zelf hadden gemaakt en dit was de interne nomenclatuur voor het model.
Phind-team
Sommige mensen suggereerden dat een partnerschap of een samenwerking tussen de twee partijen meer zou doen om de ontwikkeling van AI te bevorderen dan erover te discussiëren. De waarheid is dat AI-ontwikkeling altijd grotendeels open source is, dus modellen zullen vergelijkbare, zo niet exacte trainingspatronen hebben.
Als uw AI-model echter is getraind op het trainingspatroon van een ander model, is het alleen maar eerlijk om het werk te erkennen. Dit zou immers de basis kunnen zijn van een lange en vruchtbare samenwerking.
Wat vind jij van deze situatie?