- Microsoft bleibt seiner Aufgabe treu und verbessert ständig die gesamte Teams-Erfahrung.
- Nach großen Verbesserungen an der Audiofront fügt der Technologieriese weitere Optimierungen hinzu.
- Änderungen waren aufgrund möglich Trainieren eines konvolutionellen neuronalen Netzes auf einem Trainingssatz.
- Das Modell wurde an einer Sammlung getestet von 1.000 Audioclips, was eine Genauigkeit von 81 % ergab.

Hybride Arbeit ist die einzige praktikable Lösung, auf die Unternehmen auf der ganzen Welt nach Beginn der COVID-19-Pandemie zurückgreifen könnten.
Obwohl viele Unternehmen aufgrund der aktuellen globalen Situation den Bach runtergingen, gelang es den meisten, sich über Wasser zu halten und weiter zu funktionieren.
Es wird Sie nicht überraschen, dass Microsoft Teams eine der größten und beliebtesten Plattformen für Konferenzen und Kommunikation während dieser Homeoffice-Situation ist.
Die App wird ein- oder sogar zweimal im Monat aktualisiert, und der Technologieriese aus Redmond tut alles, um sicherzustellen, dass die Benutzer alles, was sie brauchen, zur Hand haben.
Jetzt hat Microsoft die Einführung einiger angekündigt Audio-Verbesserungen, und obwohl nicht alle neu sind, sind sie sicherlich willkommen.
Microsoft führt eine neue Funktion für die Teams-App ein
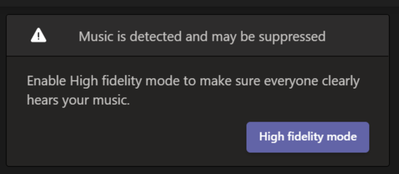
Eine der Teams-Funktionen, die Microsoft kürzlich eingeführt hat, ist die High-Fidelity-Musikmodus. Eine der neuen Ergänzungen, die den High-Fidelity-Musikmodus nutzt, ist die auf maschinellem Lernen basierende Rauschunterdrückung.
Dieses Modell verwendet Nicht-Sprachsignale als Eingabe und bestimmt dann, ob es dieses Rauschen unterdrücken soll oder nicht.
Und wenn es die Eingabe als Musik identifiziert, wie sie beispielsweise während einer Geigenstunde gespielt wird, warnt es den Benutzer, dass er den High-Fidelity-Musikmodus aktivieren sollte.
Wenn es ein falsches positives Ergebnis erkennt, kann der Benutzer dieses Banner einfach schließen. Und wenn das ML-Modell tatsächlich unerwünschte Geräusche erkennt, die keine Musik sind, unterdrückt es diese automatisch.
Redmond-Beamte sagen, dass es dieses Modell aufgebaut hat, indem es ein konvolutionelles neuronales Netzwerk auf einem Trainingsset trainiert hat, das eine Million Audioclips mit Ton und Musik enthält.
Das Trainingsset enthielt Klänge aus einer Vielzahl von Umgebungen und Instrumenten, um einer Vielzahl von Anwendungsfällen gerecht zu werden.
Außerdem wurde das Ausgabemodell dann an einer Sammlung von 1.000 Audioclips getestet, was eine Genauigkeit von 81 % ergab.
Microsoft behauptet, dass sein Modell alle veröffentlichten Forschungsergebnisse auf diesem Gebiet übertroffen hat, und Sie können das Forschungspapier hier einsehen.
Die ML-basierte Rauschunterdrückung ist jetzt für die meisten Teams-Benutzer standardmäßig aktiviert, während die automatische Musikerkennung in den kommenden Monaten allgemein eingeführt wird.
Welche anderen interessanten Funktionen sollte der Technologieriese Ihrer Meinung nach für Teams testen? Teilen Sie uns Ihre Gedanken im Kommentarbereich unten mit.