AI-udviklinger er for det meste open source, så AI-modeller trænes på lignende træningsmønstre.
- WizardLM, eller WizardCoder, er en af de bedste AI-kodere på markedet lige nu.
- WizardLM hævder, at Phind, en konkurrent, brugte WizardCoder-modellen til at træne sig selv uden at kreditere det originale arbejde.
- Virksomheden bag Phind afviser påstandene fra WizardLM.

Husk WizardCoder, AI-koderen, som vi for nylig dækkede her på Windows Report? Vi udråbte som den bedste AI-koder i verden, dengang og med god grund. WizardCoder, som også går under navnet WizardLM, er i stand til at skrive kodeblokke korrekt af sig selv. Og som et AI-værktøj kan det i høj grad hjælpe programmører med at kode hurtigere.
Og dets omdømme er vokset så meget, at det ser ud til, at WizardLMs træningsproces er blevet replikeret til en tredjeparts AI-model, kaldet Phind. Men her er fangsten: Det Microsoft-finansierede team bag WizardLM hævder, at Phind-teamet stjal alt deres arbejde uden selv at kreditere dem.
Hvis du husker,
WizardLM er en open source-model, der kan bruges til at træne din egen AI-model. Imidlertid, AI-partnerskaber er den egentlige drivkraft bag AI-udvikling, og WizardLM-teamet vil bare gerne krediteres, når deres arbejde bruges til at træne andre AI-modeller.Virksomheden bag Phind, afviser dog, at det har brugt WizardLM til at bygge modellen, selvom WizardLM-teamet har beviser, der beviser, at deres arbejde faktisk blev brugt til at skabe tredjeparts Phind-modellen.
WizardLM og Phind: En første dokumenteret fejde mellem AI-modeller
Ifølge WizardLM:
- Phind bruger et data ved navn WizardCoder-stil datasæt udført fra WizardCoder Evol-Instruct metoden til at træne deres V1 Code Llama model.
- Derefter fortsætter de med at bruge metoder fra en WizardCoder-model til at træne deres V2-model.
- De anerkender ikke brugen, og de hævder, at de ikke bruger noget fra WizardCoder.
Alle disse blev opdaget og pågrebet med billeder og skærmbilleder, der beskriver den tilsyneladende konflikt. På den anden side siger Phind-teamet, at de ikke brugte WizardLM-modellen til at træne Phind.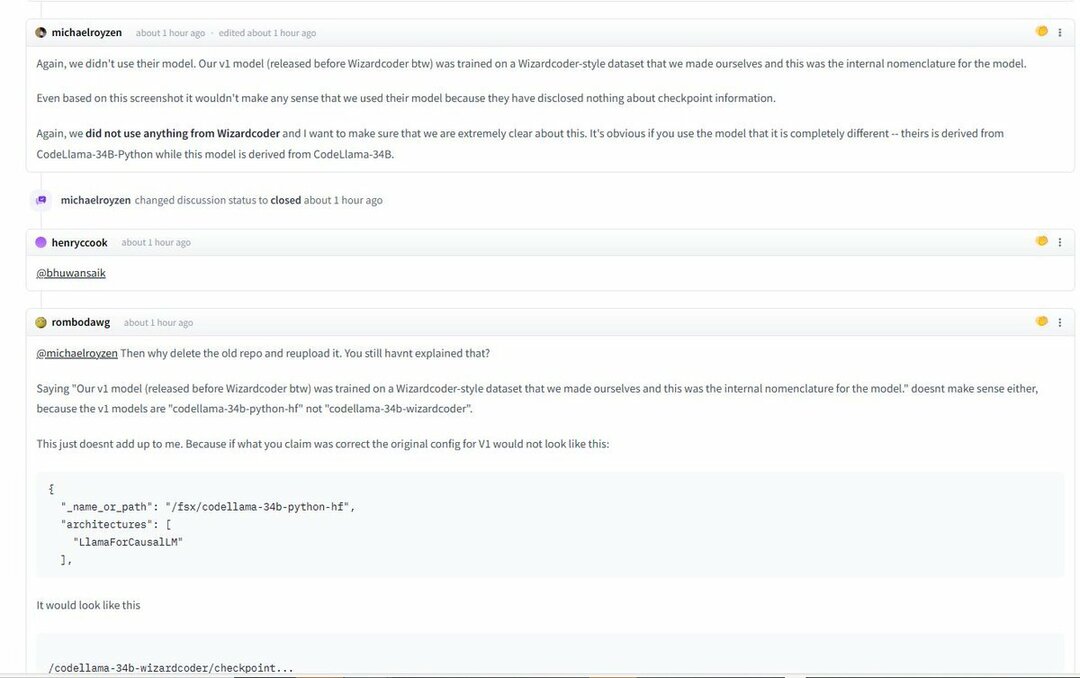
Igen brugte vi ikke deres model. Vores v1-model (udgivet før WizardCoder) blev trænet på et WizardCoder-stil datasæt, som vi selv lavede, og dette var den interne nomenklatur for modellen.
Phind team
Nogle mennesker foreslog, at et partnerskab eller et samarbejde mellem de to parter ville gøre mere for at fremme AI-udvikling end at skændes om det. Sandheden er, at AI-udvikling for det meste er open source, hele tiden, så modeller vil have lignende, hvis ikke nøjagtige træningsmønstre.
Men hvis din AI-model er trænet på en anden models træningsmønster, så er det kun rimeligt at kreditere arbejdet. Det kan trods alt være grundlaget for et langt og frugtbart partnerskab.
Hvad synes du om denne situation?


