Vývoj umělé inteligence je většinou open source, takže modely umělé inteligence jsou trénovány na podobných vzorech školení.
- WizardLM nebo WizardCoder je jedním z nejlepších kodérů AI na trhu právě teď.
- WizardLM tvrdí, že Phind, konkurent, použil model WizardCoder k trénování, aniž by připsal původní dílo.
- Společnost stojící za Phindem popírá tvrzení WizardLM.

Pamatujte si WizardCoder, AI kodér, o kterém jsme se nedávno zabývali zde ve Windows Report? Nabízeli jsme jako nejlepší AI kodér na světě, tehdy a z dobrého důvodu. WizardCoder, který se také nazývá WizardLM, je schopen sám správně zapisovat bloky kódu. A jako nástroj AI může výrazně pomoci programátorům rychleji kódovat.
A jeho pověst vzrostla natolik, že se zdá, že tréninkový proces WizardLM byl replikován do modelu umělé inteligence třetí strany, zvaného Phind. Ale tady je háček: tým financovaný Microsoftem za WizardLM tvrdí, že tým Phind ukradl veškerou jejich práci, aniž by jim to připsal.
Pokuď si pamatuješ, WizardLM je model s otevřeným zdrojovým kódem, který lze použít k trénování vlastního modelu umělé inteligence. Nicméně,
AI partnerství jsou skutečnou hnací silou vývoje umělé inteligence a tým WizardLM chce být oceněn, když je jejich práce využita k výcviku jiných modelů umělé inteligence.Společnost stojící za Phind, však popírá, že k vytvoření modelu použil WizardLM, přestože tým WizardLM má důkazy, které dokazují, že jejich práce byla skutečně použita k vytvoření modelu Phind třetí strany.
WizardLM a Phind: První zdokumentovaný spor mezi modely AI
Podle WizardLM:
- Phind používá data nazvaná datová sada ve stylu WizardCoder vytvořená metodou WizardCoder Evol-Instruct k trénování jejich modelu V1 Code Llama.
- Poté pokračují v používání metod z modelu WizardCoder k trénování svého modelu V2.
- Neuznávají použití a tvrdí, že nic z WizardCoder nepoužívají.
Všichni tito byli spatřeni a zadrženi s obrázky a snímky obrazovky s podrobnostmi o zjevném konfliktu. Na druhé straně tým Phind říká, že k trénování Phind nepoužil model WizardLM.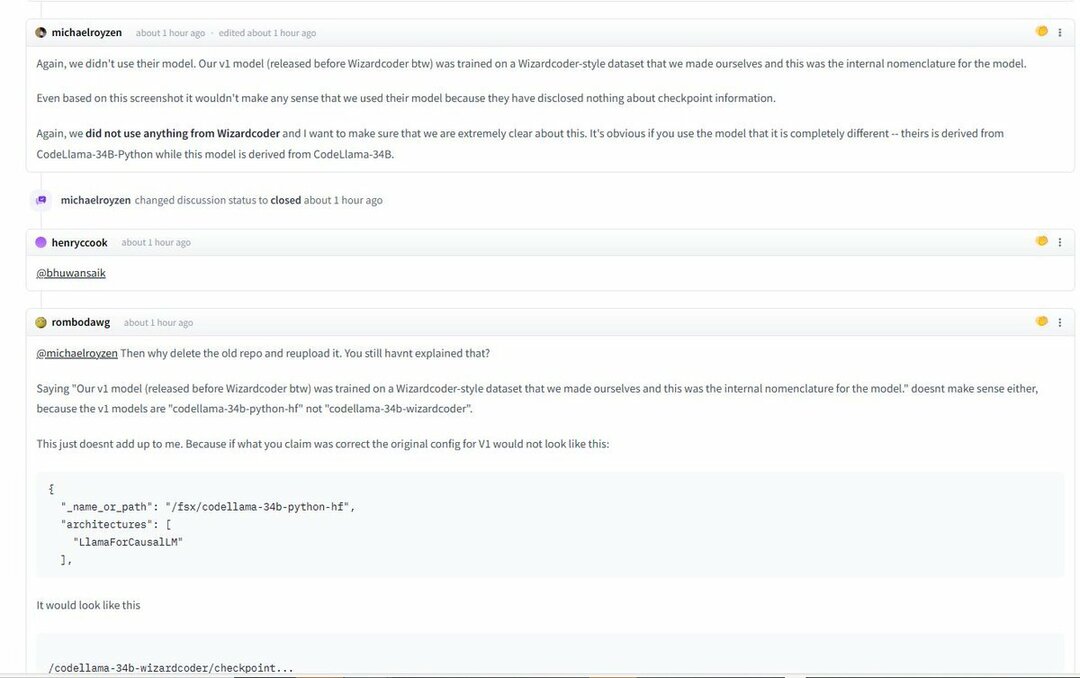
Opět jsme nepoužili jejich model. Náš model v1 (vydaný před WizardCoder) byl trénován na datové sadě ve stylu WizardCoder, kterou jsme sami vytvořili, a toto byla interní nomenklatura modelu.
Tým Phind
Někteří lidé navrhli, že partnerství nebo spolupráce mezi těmito dvěma stranami by pro rozvoj umělé inteligence udělalo více než se o tom dohadovat. Pravda je, že vývoj umělé inteligence je většinou open source, a to po celou dobu, takže modely budou mít podobné, ne-li přesné tréninkové vzorce.
Pokud je však váš model umělé inteligence trénován na cvičném vzoru jiného modelu, pak je spravedlivé ocenit práci. To by ostatně mohl být základem dlouhého a plodného partnerství.
Co si o této situaci myslíte?