معظم تطورات الذكاء الاصطناعي مفتوحة المصدر، لذلك يتم تدريب نماذج الذكاء الاصطناعي على أنماط تدريب مماثلة.
- يعد WizardLM، أو WizardCoder، واحدًا من أفضل برامج تشفير الذكاء الاصطناعي في السوق حاليًا.
- يدعي WizardLM أن Phind، أحد المنافسين، استخدم نموذج WizardCoder لتدريب نفسه، دون الاعتماد على العمل الأصلي.
- تنفي الشركة التي تقف وراء Phind الادعاءات التي قدمتها WizardLM.

تذكر ويزاردكودر، برنامج ترميز الذكاء الاصطناعي الذي قمنا بتغطيته مؤخرًا هنا في Windows Report؟ نحن توصف بأنها أفضل مبرمج للذكاء الاصطناعي في العالم، في ذلك الوقت، ولسبب وجيه. WizardCoder، والذي يحمل أيضًا اسم WizardLM، قادر على كتابة مجموعات من التعليمات البرمجية بشكل صحيح بنفسه. وباعتبارها أداة للذكاء الاصطناعي، يمكنها مساعدة المبرمجين بشكل كبير على البرمجة بشكل أسرع.
وقد نمت سمعتها كثيرًا لدرجة أنه يبدو أن عملية التدريب الخاصة بـ WizardLM قد تم تكرارها في نموذج ذكاء اصطناعي تابع لجهة خارجية، يسمى Phind. ولكن هنا تكمن المشكلة: يدعي الفريق الذي تموله Microsoft والذي يقف وراء WizardLM أن فريق Phind سرق كل أعمالهم، حتى دون أن ينسب إليهم الفضل.
اذا تذكرت، معالجLM هو نموذج مفتوح المصدر يمكن استخدامه لتدريب نموذج الذكاء الاصطناعي الخاص بك. لكن، شراكات الذكاء الاصطناعي هم القوة الدافعة الحقيقية وراء تطوير الذكاء الاصطناعي، ويريد فريق WizardLM فقط أن يُنسب إليه الفضل عندما يتم استخدام عملهم لتدريب نماذج الذكاء الاصطناعي الأخرى.
الشركة وراء Phindومع ذلك، تنفي أنها استخدمت WizardLM لبناء النموذج، على الرغم من أن فريق WizardLM لديه أدلة تثبت أن عملهم قد تم استخدامه بالفعل لإنشاء نموذج Phind لجهة خارجية.
WizardLM وPhind: أول عداء موثق بين نماذج الذكاء الاصطناعي
وفقًا لـ WizardLM:
- يستخدم Phind مجموعة بيانات تسمى مجموعة بيانات على غرار WizardCoder تم إجراؤها من طريقة WizardCoder Evol-Instruct لتدريب نموذج V1 Code Llama الخاص بهم.
- ثم يستمرون في استخدام أساليب من نموذج WizardCoder لتدريب نموذج V2 الخاص بهم.
- إنهم لا يعترفون بالاستخدام ويزعمون أنهم لا يستخدمون شيئًا من WizardCoder.
تم رصد كل هؤلاء والقبض عليهم بالصور ولقطات الشاشة التي توضح تفاصيل الصراع الظاهري. على الجانب الآخر، يقول فريق Phind أنهم لم يستخدموا نموذج WizardLM لتدريب Phind.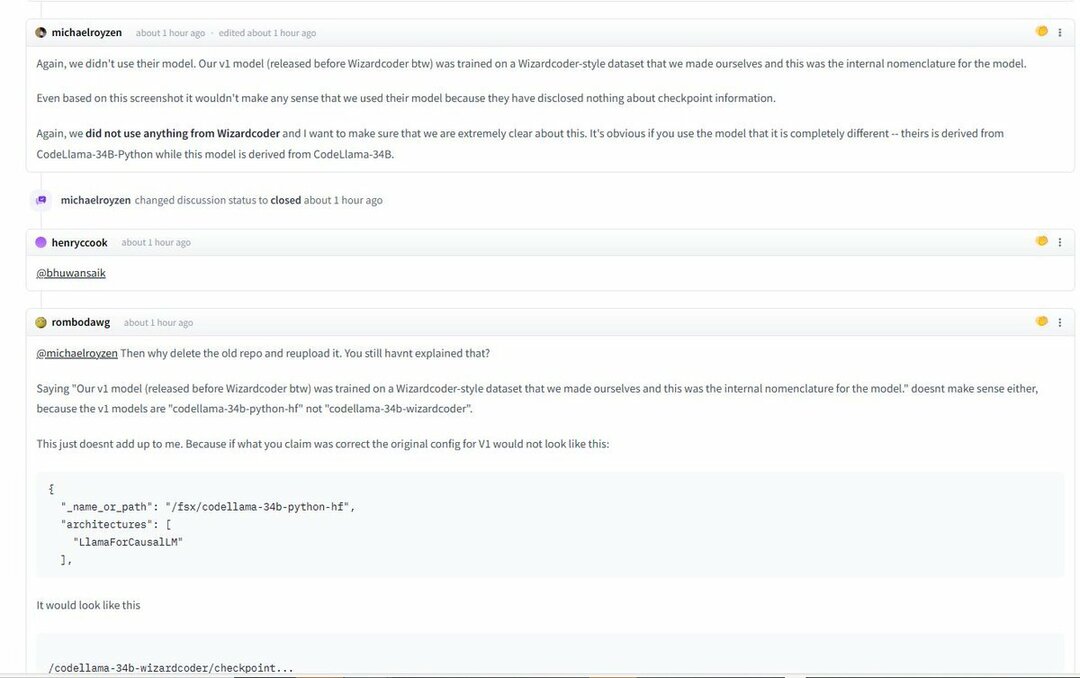
ومرة أخرى، لم نستخدم نموذجهم. تم تدريب نموذج v1 الخاص بنا (الذي تم إصداره قبل WizardCoder) على مجموعة بيانات على طراز WizardCoder صنعناها بأنفسنا وكانت هذه هي التسمية الداخلية للنموذج.
فريق فيند
اقترح بعض الأشخاص أن الشراكة أو التعاون بين الطرفين من شأنه أن يفعل المزيد لتعزيز تطوير الذكاء الاصطناعي بدلاً من الجدل حوله. الحقيقة هي أن تطوير الذكاء الاصطناعي في الغالب مفتوح المصدر، طوال الوقت، لذلك سيكون للنماذج أنماط تدريب متشابهة، إن لم تكن دقيقة.
ومع ذلك، إذا تم تدريب نموذج الذكاء الاصطناعي الخاص بك على نمط تدريب نموذج آخر، فمن العدل أن ننسب الفضل إلى العمل. ففي نهاية المطاف، يمكن أن يكون هذا أساساً لشراكة طويلة ومثمرة.
ما رأيك في هذه الحالة؟

